MySQL学习笔记Ⅴ-优化
优化思路
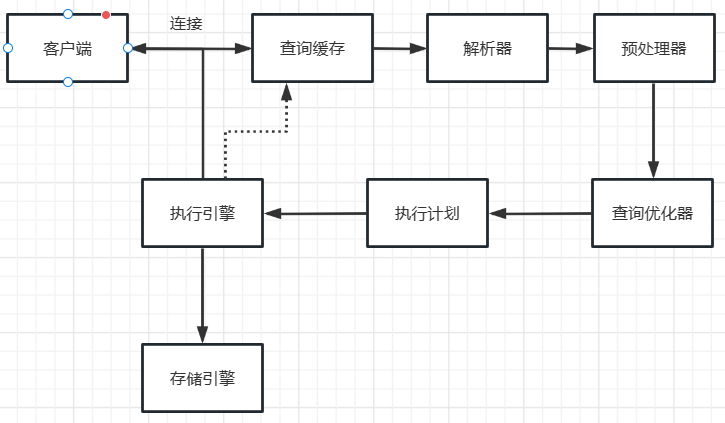
连接–配置优化
第一个环节就是客户端到服务端的连接,可能会出现服务端的连接数不够造成的性能问题。有两个解决办法:一是增加服务端的可用连接数,通过修改配置参数增加可用连接数,修改max_connections的大小show variables like 'max_connections';--修改最大连接数,或者及时释放不活动的连接。交互式和非交互式的客户端的默认超时时间都是28800秒,8小时,我们可以把这个值调小。二是,从客户端来说,可以减少从服务端获取的连接数,如果不想要每一次执行SQL都创建一个新的连接,可以引入连接池,实现连接的重用。有点像(ThreadLocal)。
缓存–架构优化
缓存
在应用系统的并发数非常大的情况下,如果没有缓存,会造成两个问题:一方面是会给数据库带来很大的压力,另一方面,从应用的层面来说,操作数据的速度也会收到影响。可以使用第三方的缓存服务来解决这个问题,如Redis。
集群、主从复制
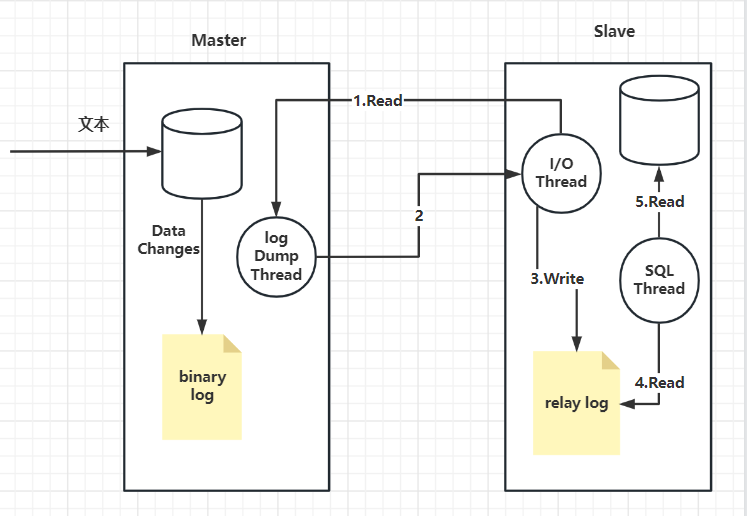
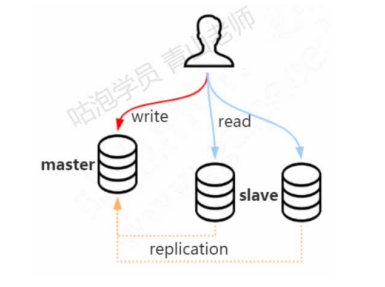
单台数据库服务满足不了访问需求,可以做数据库的集群方案。做了主从复制之后,只把数据写入master节点,而读的请求可以分担到slave节点。这种方案叫做读写分离。
读写分离可以一定程度减轻数据库服务器的访问压力,但是需要特别注意主从数据一致性的问题。
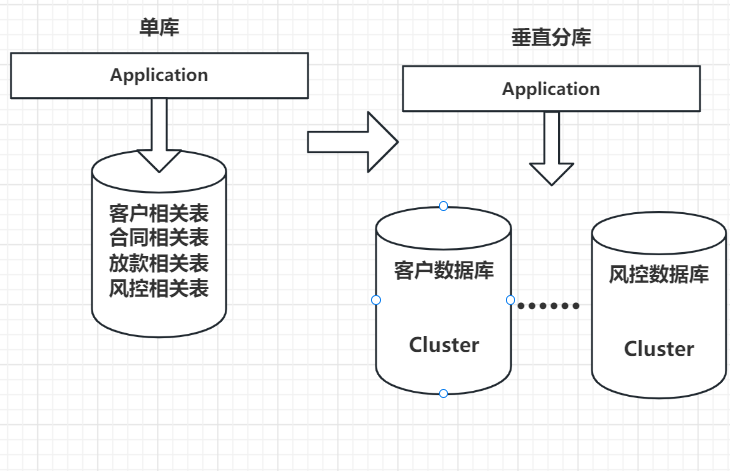
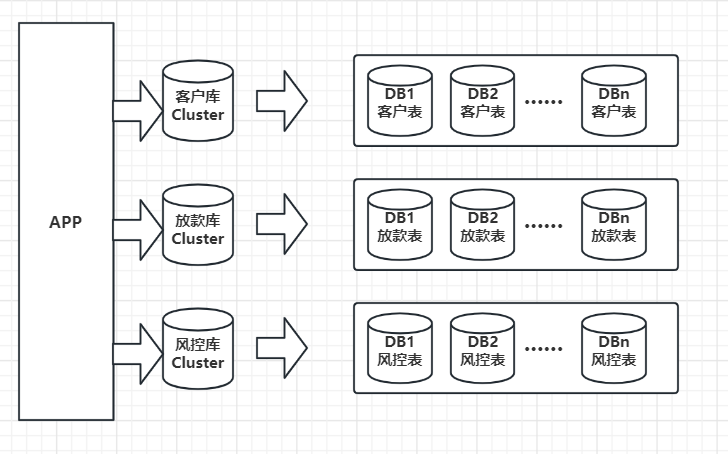
分库分表
垂直分库,减少并发压力。水平分表,解决存储瓶颈。
垂直分库的做法,是把一个数据库按照业务拆分成不同的数据库:
水平分表的做法,是把单张表的数据按照一定的规则分布到多个数据库。
优化器–SQL语句分析与优化
慢查询日志 slow query log
打开慢日志开关:打开是有代价的,所以默认关闭。
show variables like 'slow_query%'。除了这个开关还有一个参数,控制执行超过多长时间的SQL才记录到慢日志,默认是十秒,改成0秒的话就是记录所有的SQL。show variables like '%long_query%';。可以直接动态修改参数(重启后失效):、1
2
3
4show variables like '%long_query%';set @@global.slow_query_log=1; -- 1开启 0关闭 重启后失效
set @@global.long_query_time=3; -- msyql默认的慢查询时间是10秒,另开一个窗口后才会查到最新值
show variables like 'slow_query%'
show variables like '%long_query%';或者修改配置文件my.cnf:
1
2
3slow_query_log=ON
long_query_time=2
slow_query_log_file=/var/lib/mysql/localhost-slow.log慢日志分析
1
2show global status like 'slow_queries'; -- 查看有多少,慢查询
show variables like '%slow_query%'; -- 获取慢日志目录mysqldumpslow:是MySQL提供的一个慢日志分析工具,在MySQL的bin目录下
mysqldumpslow --help例如:查询用时最多的10条慢SQL:
mysqldumpslow -s -t 10 -g 'select' /var/lib/mysql/localhost-slow.log
Count:表示这个SQL执行了多少次
Time:代表执行的时间,括号里面是累计时间
Lock:表示锁定的时间,括号是累计
Rows:表示返回的记录数,括号是累计
SHOW PROFILE
可以查看SQL语句执行的时候使用的资源,比如CPU、IO的消耗情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20select @@profiling; -- 查看是否开启
set @@profiling=1; -- 开启
-- 查看profile统计
show profiles;
-- 查看最后一个SQL的执行详细信息,从中找出耗时较多的环节
show profile;
-- 也可以根据ID查看执行详细信息,在后面带上 for query +ID
show profile for query 1;
-- 其他系统命令
-- 分析server层的运行信息,可以用show status
show global status; -- 用于查看MySQL服务器运行状态(重启后会清空)
-- 可以用like通配符过滤,例如查看select语句的执行次数
show global status like 'com_select'; -- 查看select次数
-- 如果要分析服务层的连接信息,可以用:
show processlist; -- 用于显示用户运行线程 可以用kill id 杀掉指定线程
-- 也可以查表,效果一样
select * from information_schema processlist;
-- 显示存储引擎的当前运行信息,包括事务持有的表锁、行锁信息;事务的锁等待况;线程信号量;文件IO请求;buffer pool统计信息
show engine;
show engine innodb status;通过上述的种种操作,我们可以知道哪些SQL慢,且慢在哪。MySQL又提供了一个执行计划的工具,通过EXPLAIN可以模拟优化器执行SQL查询语句的过程,来知道MySQL是怎么处理一条SQL语句的。通过这种方式我们可以分析语句或者表的性能瓶颈。
EXPLAIN执行计划

select_type查询类型,还有其他:DEPENDENT UNION、DEPENDENT SUBQUERY、MATERIALIZED、UNCACHEABLE SUBQUERY、UNCACHEABLE UNION。
常见的查询类型:
SIMPLE:简单查询,不包含子查询和关联查询union。
PRIMARY:子查询SQL语句中的主查询,也就是最外面的那层查询。
SUBQUERY:子查询中所有的内层查询都是SUBQUERY类型的。
DERIVED:派生查询,表示在得到最终查询结果之前会用到临时表。
UNION:用到了UNION查询(UNION会用到内部的临时表)。UNION ALL不需要去重,因此不用临时表。
UNION RESULT:主要是显示哪些表之间存在UNION查询。
例如:
1
2
3
4
5
6-- 查询ID为1或2的老师教授的课程
EXPLAIN SELECT cr.name
FROM(
SELECT * FROM course WHERE tid=1
UNION
SELECT * FROM course WHERE tid=2)cr;对于关联查询,先执行右边的table(UNION),在执行左边的table,类型是DERIVED。
type,在常用的连接类型中:system>const>eq_ref>ref>range>index>all,其他还有fulltext、ref_or_null、index_merger、unique_subquery、index_subquery。以上除了all,都能用到索引。
const:主键索引或者唯一索引与常数进行等值匹配,只能查到一条数据的SQL。
system:是const的一种特例,只有一行满足条件,对于MyISAM、Memory的表,只查询到一条记录,也是system。
eq_ref:通常出现在多表的join查询,被驱动表通过唯一性索引(UNIQUE或PRIMARY KEY)进行访问,此时被驱动表的访问方式就是eq_ref。eq_ref是除const之外最好的访问形式。
以上三个访问方式都是可遇不可求的,基本上很难优化的这个状态。
ref:查询用到了非唯一索引
range:对索引进行范围扫描。不走索引一定是全表扫描(ALL),IN查询也是range(字段有主键索引)
index:Full Index Scan,查询全部索引中的数据(比不走索引快)
EXPLAIN SELECT tid FROM teacher;ALL:FULL Table Scan,如果没有索引,type就是ALL。代表全表扫描。
一般来说,需要保证查询至少打到range级别,最好能达到ref。ALL(全表扫描)和index(查询全部索引)都是需要优化的。
possible_key、key:可能用到的索引和实际用到的索引。如果是NULL就代表没有用到的索引。possible_key可以有一个或者多个,比如查询多个字段都有索引,或者一个字段同时有单列索引和联合索引。能用到的索引并不是越多越好。可能用到索引不代表一定用到索引。如果通过分析发现没有用到索引,就要检查SQL或者创建索引。
key_len:所以的长度(使用的字节数)。跟索引字段的类型、长度有关。表上有联合索引:KEY `comidx_name_phone`(`name`,`phone`):
explain select * from user_innodb where name='XXX'这里索引只用到了name字段,utf8mb4编码1字符4字节。所以是255*4=1020.使用变长字段varchar需要额外增加2字节,允许NULL需要额外增加1字节。一共是1023=key_len。rows:MySQL认为扫描多少行(数据或索引)才能返回请求的数据,是一个预估值,一般来说行数越少越好。
filtered:表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,是一个百分比。如果比例很低,说明存储引擎层返回的的数据需要经过大量的过滤,这个是会消耗性能的。
ref:使用哪个列或者常数和索引一起从表中筛选数据,可以参考一下。(???)
extra:执行额外计划给出的额外的信息说明。
如果需要具体的cost信息,可以用 EXPLAIN FORMAT=JSON,可以开启optimizer trace获得更详细的信息。
存储引擎
存储引擎的选择
为不同的业务表选择不同的存储引擎,例如:查询插入操作多的业务表,用MyISAM。临时数据用Memory。常规的并发大更新多的表用innodb。
字段定义
原则:使用可以正确存储数据的最小数据类型。为每一列选择合适的字段类型。
- 整数类型:tinyint、smallint、mediumint、int、integer、bigint、bit,enum
- 字符类型:变长varchar更节省空间,但要多一个字节来记录长度。固定长度用char。
- 不要使用外键、触发器、视图:降低了可读性。影响数据库性能,应该把计算的事情交给程序,数据库专心做存储;数据完整性应该在程序中检查。
- 大文件存储:不要在数据库存储图片或者大文件。NAS,数据库只需要存储URI。
- 表拆分或者字段冗余:把不常用的字段拆分出去,避免列数过大和数据量过大、
TIPS
- 除了对SQL与索引、表定义、架构、存储引擎、配置优化外,业务层面的优化也不能忽视。比如限流、引入MQ削峰等
- SQL推荐:
- 使用小表驱动大表
- 用join来代替子查询
- not exist转换为left join IS NULL
- or 改为 union
- 使用UNION ALL代替UNION,如果结果集允许重复的话
- 大偏移的limit,先过滤再排序。
- 表结构(冗余、拆分、not null等)、架构优化
- 业务层优化,必须条件是否必要